
We audited the robots.txt files of 45 major companies. More than half are blocking AI crawlers. Most don’t realize they’re also blocking the bots that index sites for AI search answers, the ones that actually send visitors back.
The finding came out of a broader AI Readiness study. We ran our snapshot tool across 20 B2B SaaS companies, 18 Fortune 20 companies, and 7 industrial manufacturers. Every audit includes a robots.txt check. The pattern was hard to miss: 25 of 45 companies (56%) actively block at least one AI crawler. Twenty-one of them (47%) use a blanket wildcard rule that blocks everything.
The second-highest scoring company in our dataset, a major payment processing platform that scored 80 out of 100 on AI readability, has a robots.txt that blocks all bots. They built one of the most AI-readable sites on the internet and then locked the door.
Two Kinds of AI Crawlers, One Block
Here’s the part most companies get wrong. AI vendors have split their crawlers into two categories, and most blocking rules treat them as the same thing.
Training crawlers collect pages to build and refine models. GPTBot, ClaudeBot, Google-Extended, and Bytespider fall into this group. They take your content, turn it into model weights, and you never hear from them again. The crawl-to-referral ratio is lopsided. Cloudflare’s network research measured Anthropic at 70,900 pages crawled for every one visitor referred at its June 2025 peak. OpenAI sat at 1,091:1. For comparison, traditional Googlebot runs about 5 pages crawled per referral.
Search crawlers index your site so you appear as a cited source in AI-generated answers. OAI-SearchBot powers ChatGPT search results. Claude-SearchBot indexes for Claude’s web search. PerplexityBot builds Perplexity’s answer engine. These crawlers send traffic back. Blocking them means your site won’t appear in AI search answers, regardless of how well-structured your content is.
The two categories share a parent company but nothing else. Blocking GPTBot does not block OAI-SearchBot. Blocking ClaudeBot does not block Claude-SearchBot. The user-agent strings are different. The robots.txt rules that govern them are independent. A site can block every training crawler while allowing every search crawler. Most companies don’t.
How the Blocking Happens
Three paths lead to the same outcome.
Path 1: Cloudflare’s one-click block. Cloudflare launched a “Block AI Bots” toggle that now ships enabled on many accounts. It blocks every AI crawler indiscriminately, training and search alike. For companies on Cloudflare’s CDN (a significant portion of the web), this single toggle can remove a site from AI search results without anyone making a deliberate decision.
Path 2: Wildcard robots.txt rules. Many enterprise sites use User-agent: * Disallow: / in robots.txt. This tells every bot, including AI search crawlers, to stay away. It’s often a legacy security posture rather than a considered AI strategy. Twenty-one of the 45 companies in our dataset use this pattern.
Path 3: WAF and bot detection. Enterprise security systems like Akamai Bot Manager, Cloudflare Bot Fight Mode, and Imperva flag AI crawlers as automated threats. The blocking happens at the network layer, before robots.txt is even consulted. Companies using these systems block AI crawlers as a side effect of anti-scraping protection, not as an intentional content decision.
One major e-commerce platform takes a more surgical approach. Their robots.txt selectively blocks five training crawlers while allowing search crawlers through. That’s a considered strategy: block training, allow search. It’s also rare. Only 7 of 45 companies in our dataset (16%) have explicit, crawler-specific rules rather than blanket blocks.
What the Data Shows
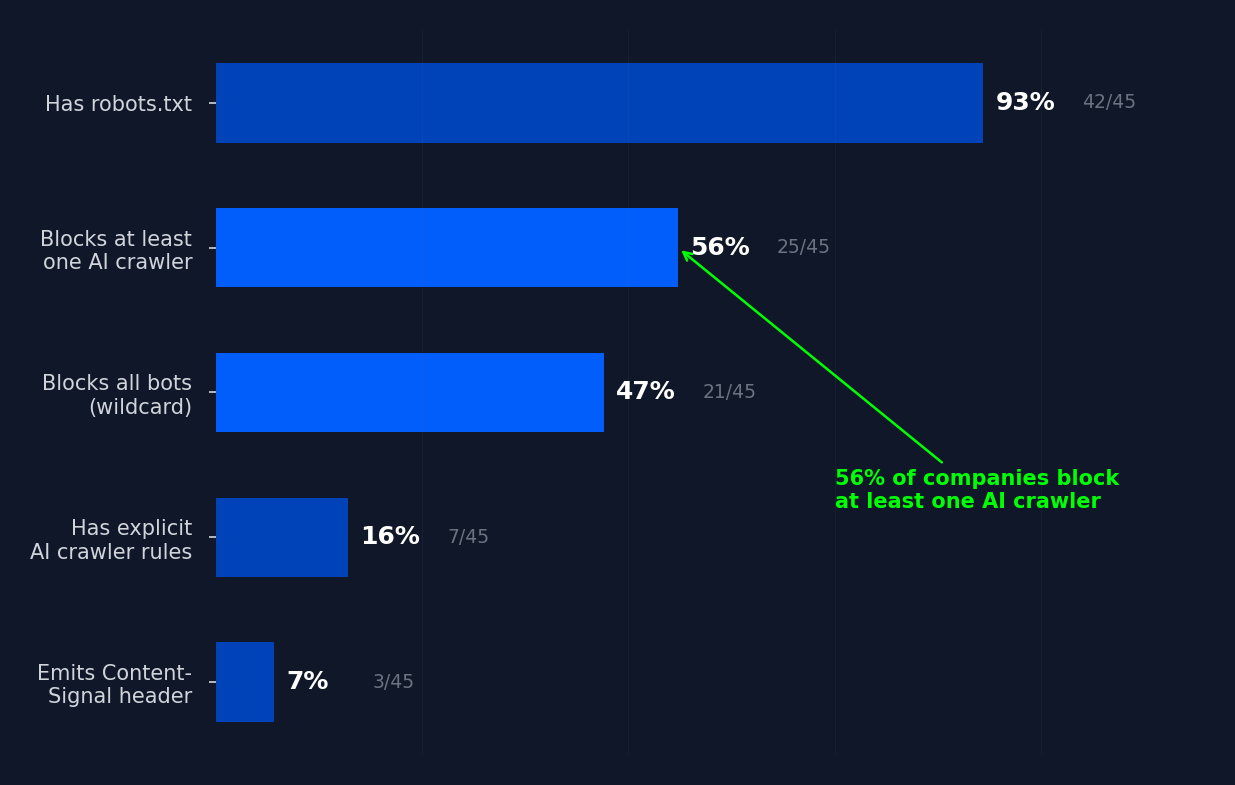
The 45-company audit reveals a landscape of accidental blocking.
| Finding | Count | Percentage |
|---|---|---|
| Has robots.txt | 42 of 45 | 93% |
| Blocks at least one AI crawler | 25 of 45 | 56% |
| Blocks all bots (wildcard) | 21 of 45 | 47% |
| Has explicit AI crawler rules | 7 of 45 | 16% |
| Emits Content-Signal header | 3 of 45 | 7% |
The Content-Signal header is a newer mechanism. It declares AI training consent at the protocol level. Only two companies in the dataset emit Content-Signal: ai-train=yes. One explicitly opts out with ai-train=no, which is at least a deliberate choice.
The wildcard blockers include some of the most recognizable companies in the world. A top-three Fortune 100 retailer, a trillion-dollar tech company, a leading CRM platform, a major payment processor, and a top video conferencing tool. Twenty-one companies in total. Each one has a site that AI search engines cannot crawl. When a buyer asks ChatGPT or Perplexity for a recommendation, these companies rely entirely on third-party descriptions. They have no direct input into what the AI says about them.
The Economics of Blocking
Training crawlers and search crawlers have fundamentally different value exchanges.
A training crawler takes your content and gives you nothing. The model it trains can compete with you. It can generate an answer that replaces a visit to your site. The argument for blocking training crawlers is straightforward. Your content cost money to produce. The AI company gets it for free. The return traffic is effectively zero.
A search crawler takes your content and gives you a citation. That citation appears in an answer that a buyer is actively reading. When a prospect asks an AI assistant for a recommendation, the answer cites two or three sources. Each citation is a link. Some users click it. That click is a referral you can track in your analytics.
AI-referred traffic is growing. Cloudflare reports that search-based crawling now accounts for only about 15% of AI bot activity, while training drives roughly 82%. Companies are receiving 5x the crawling pressure from training bots that give nothing back, and their response is to block the 15% that do. This is the same pattern we see in companies that don’t show up in AI answers at all. They’ve confused the cause with the solution.
The Fix
The correct configuration for most companies is a robots.txt that blocks training crawlers and allows search crawlers. The distinction is already supported by the major AI vendors. OpenAI, Anthropic, Google, Amazon, and Apple each operate separate user-agent strings for training and search.
A typical configuration looks like this:
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Allow: /This blocks the crawlers that extract value without returning traffic, and allows the ones that index for AI search answers. It takes about ten minutes to implement for someone with access to the robots.txt file.
If your site uses Cloudflare’s “Block AI Bots” toggle, check whether it’s blocking OAI-SearchBot and Claude-SearchBot. If your robots.txt uses User-agent: * Disallow: /, you’re blocking AI search crawlers you didn’t know existed.
Why This Matters
AI search is not a future trend. It’s a present channel. Perplexity answers queries with cited sources. ChatGPT search returns links. Claude’s web search recommends sites. Apple’s Siri now surfaces web-sourced answers across 2.5 billion devices. When a buyer asks a question in one of these tools, the AI consults its search index. If your site isn’t in that index because you blocked the crawler, you don’t appear in the answer. No amount of schema markup, Evidence Strength, or brand recognition can compensate.
The 47% of companies in our dataset with blanket bot blocks have made a choice. Most of them don’t know they made it. The robots.txt file was probably copied from a template, set up by a developer who left two years ago, or enabled by a Cloudflare toggle that seemed like a security best practice.
The irony is that the companies best positioned to benefit from AI search, the ones with the strongest content and the best-structured sites, are often the ones blocking the crawlers that would surface their work. The top-scoring payment platform in our dataset locked an exceptional site behind a wildcard rule. A major website builder that publicly markets its own AI readiness tools blocks all bots. A prominent marketing software company blocks the crawlers that would index their educational content.
The first step is knowing which crawlers are blocked. The second step is knowing which ones send traffic. Most companies haven’t done either.




Find Out What AI Tells Buyers About You
An AI visits your site and reports everything it found. Scored across six categories with machine-verifiable findings. No cost, no pitch.
Get Your Free Snapshot